
Chapter Two Introduction to Character Strings
2.1 Chapter Overview
This chapter discusses how to declare and use character strings in your programs. While not a complete treatment of this subject (additional material appears later in this text), this chapter will provide sufficient information to allow basic string manipulation within your HLA programs.
2.2 Composite Data Types
Composite data types are those that are built up from other (generally scalar) data types. This chapter will cover one of the more important composite data types - the character string. A string is a good example of a composite data type - it is a data structure built up from a sequence of individual characters and some other data.
2.3 Character Strings
After integer values, character strings are probably the most popular data type that modern programs use. The 80x86 does support a handful of string instructions, but these instructions are really intended for block memory operations, not a specific implementation of a character string. Therefore, this section will concentrate mainly on the HLA definition of character strings and also discuss the string handling routines available in the HLA Standard Library.
In general, a character string is a sequence of ASCII characters that possesses two main attributes: a length and the character data. Different languages use different data structures to represent strings. To better understand the reasoning behind HLA strings, it is probably instructive to look at two different string representations popularized by various high level languages.
Without question, zero-terminated strings are probably the most common string representation in use today because this is the native string format for C/C++ and programs written in C/C++. A zero terminated string consists of a sequence of zero or more ASCII characters ending with a byte containing zero. For example, in C/C++, the string "abc" requires four characters: the three characters `a', `b', and `c' followed by a byte containing zero. As you'll soon see, HLA character strings are upwards compatible with zero terminated strings, but in the meantime you should note that it is very easy to create zero terminated strings in HLA. The easiest place to do this is in the STATIC section using code like the following:
static zeroTerminatedString: char; @nostorage; byte "This is the zero terminated string", 0;Remember, when using the @NOSTORAGE option, no space is actually reserved for a variable declaration, so the zeroTerminatedString variable's address in memory corresponds to the first character in the following BYTE directive. Whenever a character string appears in the BYTE directive as it does here, HLA emits each character in the string to successive memory locations. The zero value at the end of the string properly terminates this string.
Zero terminated strings have two principle attributes: they are very simple to implement and the strings can be any length. On the other hand, zero terminated string haves a few drawbacks. First, though not usually important, zero terminated strings cannot contain the NUL character (whose ASCII code is zero). Generally, this isn't a problem, but it does create havoc once in a great while. The second problem with zero terminated strings is that many operations on them are somewhat inefficient. For example, to compute the length of a zero terminated string you must scan the entire string looking for that zero byte (counting each character as you encounter it). The following program fragment demonstrates how to compute the length of the string above:
mov( &zeroTerminatedString, ebx ); mov( 0, eax ); while( (type byte [ebx]) <> 0 ) do inc( ebx ); inc( eax ); endwhile; // String length is now in EAX.As you can see from this code, the time it takes to compute the length of the string is proportional to the length of the string; as the string gets longer it will take longer to compute its length.
A second string format, length-prefixed strings, overcomes some of the problems with zero terminated strings. Length-prefixed strings are common in languages like Pascal; they generally consist of a length byte followed by zero or more character values. The first byte specifies the length of the string, the remaining bytes (up to the specified length) are the character data itself. In a length-prefixed scheme, the string "abc" would consist of the four bytes $03 (the string length) followed by `a', `b', and `c'. You can create length prefixed strings in HLA using code like the following:
data lengthPrefixedString:char; byte 3, "abc";Counting the characters ahead of time and inserting them into the byte statement, as was done here, may seem like a major pain. Fortunately, there are ways to have HLA automatically compute the string length for you.
Length-prefixed strings solve the two major problems associated with zero-terminated strings. It is possible to include the NUL character in length-prefixed strings and those operations on zero terminated strings that are relatively inefficient (e.g., string length) are more efficient when using length prefixed strings. However, length prefixed strings suffer from their own drawbacks. The principal drawback to length-prefixed strings, as described, is that they are limited to a maximum of 255 characters in length (assuming a one-byte length prefix).
HLA uses an expanded scheme for strings that is upwards compatible with both zero-terminated and length-prefixed strings. HLA strings enjoy the advantages of both zero-terminated and length-prefixed strings without the disadvantages. In fact, the only drawback to HLA strings over these other formats is that HLA strings consume a few additional bytes (the overhead for an HLA string is nine bytes compared to one byte for zero-terminated or length-prefixed strings; the overhead being the number of bytes needed above and beyond the actual characters in the string).
An HLA string value consists of four components. The first element is a double word value that specifies the maximum number of characters that the string can hold. The second element is a double word value specifying the current length of the string. The third component is the sequence of characters in the string. The final component is a zero terminating byte. You could create an HLA-compatible string in the STATIC section using the following code1:
static dword 11; dword 11; TheString: char; @nostorage; byte "Hello there"; byte 0;Note that the address associated with the HLA string is the address of the first character, not the maximum or current length values.
"So what is the difference between the current and maximum string lengths?" you're probably wondering. Well, in a fixed string like the above they are usually the same. However, when you allocate storage for a string variable at run-time, you will normally specify the maximum number of characters that can go into the string. When you store actual string data into the string, the number of characters you store must be less than or equal to this maximum value. The HLA Standard Library string routines will raise an exception if you attempt to exceed this maximum length (something the C/C++ and Pascal formats can't do).
The terminating zero byte at the end of the HLA string lets you treat an HLA string as a zero-terminated string if it is more efficient or more convenient to do so. For example, most calls to Windows and Linux require zero-terminated strings for their string parameters. Placing a zero at the end of an HLA string ensures compatibility with Windows, Linux, and other library modules that use zero-terminated strings.
2.4 HLA Strings
As noted in the previous section, HLA strings consist of four components: a maximum length, a current string length, character data, and a zero terminating byte. However, HLA never requires you to create string data by manually emitting these components yourself. HLA is smart enough to automatically construct this data for you whenever it sees a string literal constant. So if you use a string constant like the following, understand that somewhere HLA is creating the four-component string in memory for you:
stdout.put( "This gets converted to a four-component string by HLA" );HLA doesn't actually work directly with the string data described in the previous section. Instead, when HLA sees a string object it always works with a pointer to that object rather than the object directly. Without question, this is the most important fact to know about HLA strings, and is the biggest source of problems beginning HLA programmers have with strings in HLA: strings are pointers! A string variable consumes exactly four bytes, the same as a pointer (because it is a pointer!). Having said all that, let's take a look at a simple string variable declaration in HLA:
static StrVariable: string;Since a string variable is a pointer, you must initialize it before you can use it. There are three general ways you may initialize a string variable with a legal string address: using static initializers, using the stralloc routine, or calling some other HLA Standard Library that initializes a string or returns a pointer to a string.
In one of the static declaration sections that allow initialized variables (STATIC, and READONLY) you can initialize a string variable using the standard initialization syntax, e.g.,
static InitializedString: string := "This is my string";Note that this does not initialize the string variable with the string data. Instead, HLA creates the string data structure (see the previous section) in a special, hidden, memory segment and initializes the InitializedString variable with the address of the first character in this string (the "T" in "This"). Remember, strings are pointers! The HLA compiler places the actual string data in a read-only memory segment. Therefore, you cannot modify the characters of this string literal at run-time. However, since the string variable (a pointer, remember) is in the static section, you can change the string variable so that it points at different string data.
Since string variables are pointers, you can load the value of a string variable into a 32-bit register. The pointer itself points at the first character position of the string. You can find the current string length in the double word four bytes prior to this address, you can find the maximum string length in the double word eight bytes prior to this address. The following program demonstrates one way to access this data2.
// Program to demonstrate accessing Length and Maxlength fields of a string. program StrDemo; #include( "stdlib.hhf" ); static theString:string := "String of length 19"; begin StrDemo; mov( theString, ebx ); // Get pointer to the string. mov( [ebx-4], eax ); // Get current length mov( [ebx-8], ecx ); // Get maximum length stdout.put ( "theString = `", theString, "`", nl, "length( theString )= ", (type uns32 eax ), nl, "maxLength( theString )= ", (type uns32 ecx ), nl ); end StrDemo; Program 2.1 Accessing the Length and Maximum Length Fields of a StringWhen accessing the various fields of a string variable it is not wise to access them using fixed numeric offsets as done in this example. In the future, the definition of an HLA string may change slightly. In particular, the offsets to the maximum length and length fields are subject to change. A safer way to access string data is to coerce your string pointer using the str.strRec data type. The str.strRec data type is a record data type (see "Records, Unions, and Name Spaces" on page 483) that defines symbolic names for the offsets of the length and maximum length fields in the string data type. Were the offsets to the length and maximum length fields to change in a future version of HLA, then the definitions in str.strRec would also change, so if you use str.strRec then recompiling your program would automatically make any necessary changes to your program.
To use the str.strRec data type properly, you must first load the string pointer into a 32-bit register, e.g., "MOV( SomeString, EBX );" Once the pointer to the string data is in a register, you can coerce that register to the str.strRec data type using the HLA construct "(type str.strRec [EBX])". Finally, to access the length or maximum length fields, you would use either "(type str.strRec [EBX]).length" or "(type str.strRec [EBX]).MaxStrLen" (respectively). Although there is a little more typing involved (versus using simple offsets like "-4" or "-8"), these forms are far more descriptive and much safer than straight numeric offsets. The following program corrects the previous example by using the str.strRec data type.
// Program to demonstrate accessing Length and Maxlength fields of a string. program LenMaxlenDemo; #include( "stdlib.hhf" ); static theString:string := "String of length 19"; begin LenMaxlenDemo; mov( theString, ebx ); // Get pointer to the string. mov( (type str.strRec [ebx]).length, eax ); // Get current length mov( (type str.strRec [ebx]).MaxStrLen, ecx ); // Get maximum length stdout.put ( "theString = `", theString, "`", nl, "length( theString )= ", (type uns32 eax ), nl, "maxLength( theString )= ", (type uns32 ecx ), nl ); end LenMaxlenDemo; Program 2.2 Correct Way to Access Length and MaxStrLen Fields of a StringA second way to manipulate strings in HLA is to allocate storage on the heap to hold string data. Because strings can't directly use pointers returned by malloc (since strings need to access eight bytes prior to the pointer address), you shouldn't use malloc to allocate storage for string data. Fortunately, the HLA Standard Library memory module provides a memory allocation routine specifically designed to allocate storage for strings: stralloc. Like malloc, stralloc expects a single dword parameter. This value specifies the (maximum) number of characters needed in the string. The stralloc routine will allocate the specified number of bytes of memory, plus between nine and thirteen additional bytes to hold the extra string information3.
The stralloc routine will allocate storage for a string, initialize the maximum length to the value passed as the stralloc parameter, initialize the current length to zero, and store a zero (terminating byte) in the first character position of the string. After all this, stralloc returns the address of the zero terminating byte (that is, the address of the first character element) in the EAX register.
Once you've allocated storage for a string, you can call various string manipulation routines in the HLA Standard Library to operate on the string. The next section will discuss the HLA string routines in detail; this section will introduce a couple of string related routines for the sake of example. The first such routine is the "stdin.gets( strvar )". This routine reads a string from the user and stores the string data into the string storage pointed at by the string parameter (strvar in this case). If the user attempts to enter more characters than you've allocated for the string, then stdin.gets raises the ex.StringOverflow exception. The following program demonstrates the use of stralloc.
// Program to demonstrate stralloc and stdin.gets. program strallocDemo; #include( "stdlib.hhf" ); static theString:string; begin strallocDemo; stralloc( 16 ); // Allocate storage for the string and store mov( eax, theString ); // the pointer into the string variable. // Prompt the user and read the string from the user: stdout.put( "Enter a line of text (16 chars, max): " ); stdin.flushInput(); stdin.gets( theString ); // Echo the string back to the user: stdout.put( "The string you entered was: ", theString, nl ); end strallocDemo; Program 2.3 Reading a String from the UserIf you look closely, you see a slight defect in the program above. It allocates storage for the string by calling stralloc but it never frees the storage allocated. Even though the program immediately exits after the last use of the string variable, and the operating system will deallocate the storage anyway, it's always a good idea to explicitly free up any storage you allocate. Doing so keeps you in the habit of freeing allocated storage (so you don't forget to do it when it's important) and, also, programs have a way of growing such that an innocent defect that doesn't affect anything in today's program becomes a show-stopping defect in tomorrow's version.
To free storage allocated via stralloc, you must call the corresponding strfree routine, passing the string pointer as the single parameter. The following program is a correction of the previous program with this minor defect corrected:
// Program to demonstrate stralloc, strfree, and stdin.gets. program strfreeDemo; #include( "stdlib.hhf" ); static theString:string; begin strfreeDemo; stralloc( 16 ); // Allocate storage for the string and store mov( eax, theString ); // the pointer into the string variable. // Prompt the user and read the string from the user: stdout.put( "Enter a line of text (16 chars, max): " ); stdin.flushInput(); stdin.gets( theString ); // Echo the string back to the user: stdout.put( "The string you entered was: ", theString, nl ); // Free up the storage allocated by stralloc: strfree( theString ); end strfreeDemo; Program 2.4 Corrected Program that Reads a String from the UserWhen looking at this corrected program, please take note that the stdin.gets routine expects you to pass it a string parameter that points at an allocated string object. Without question, one of the most common mistakes beginning HLA programmers make is to call stdin.gets and pass it a string variable that has not been initialized. This may be getting old now, but keep in mind that strings are pointers! Like pointers, if you do not initialize a string with a valid address, your program will probably crash when you attempt to manipulate that string object. The call to stralloc plus moving the returned result into theString is how the programs above initialize the string pointer. If you are going to use string variables in your programs, you must ensure that you allocate storage for the string data prior to writing data to the string object.
Allocating storage for a string option is such a common operation that many HLA Standard Library routines will automatically do the allocation to save you the effort. Generally, such routines have an "a_" prefix as part of their name. For example, the stdin.a_gets combines a call to stralloc and stdin.gets into the same routine. This routine, which doesn't have any parameters, reads a line of text from the user, allocates a string object to hold the input data, and then returns a pointer to the string in the EAX register. The following program is an adaptation of the previous two programs that uses stdin.a_gets:
// Program to demonstrate strfree and stdin.a_gets. program strfreeDemo2; #include( "stdlib.hhf" ); static theString:string; begin strfreeDemo2; // Prompt the user and read the string from the user: stdout.put( "Enter a line of text: " ); stdin.flushInput(); stdin.a_gets(); mov( eax, theString ); // Echo the string back to the user: stdout.put( "The string you entered was: ", theString, nl ); // Free up the storage allocated by stralloc: strfree( theString ); end strfreeDemo2; Program 2.5 Reading a String from the User with stdin.a_getsNote that, as before, you must still free up the storage stdin.a_gets allocates by calling the strfree routine. One big difference between this routine and the previous two is the fact that HLA will automatically allocate exactly enough space for the string read from the user. In the previous programs, the call to stralloc only allocates 16 bytes. If the user types more than this then the program raises an exception and quits. If the user types less than 16 characters, then some space at the end of the string is wasted. The stdin.a_gets routine, on the other hand, always allocates the minimum necessary space for the string read from the user. Since it allocates the storage, there is little chance of overflow4.
2.5 Accessing the Characters Within a String
Extracting individual characters from a string is a very common and easy task. In fact, it is so easy that HLA doesn't provide any specific procedure or language syntax to accomplish this - it's easy enough just to use machine instructions to accomplish this. Once you have a pointer to the string data, a simple indexed addressing mode will do the rest of the work for you.
Of course, the most important thing to keep in mind is that strings are pointers. Therefore, you cannot apply an indexed addressing mode directly to a string variable an expect to extract characters from the string. I.e, if s is a string variable, then "MOV( s[ebx], al );" does not fetch the character at position EBX in string s and place it in the AL register. Remember, s is just a pointer variable, an addressing mode like s[ebx] will simply fetch the byte at offset EBX in memory starting at the address of s (see Figure 2.1).
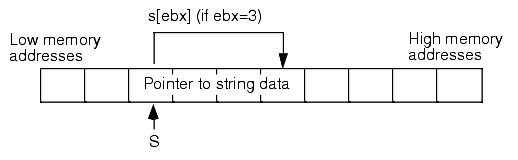
Figure 2.1 Incorrectly Indexing Off a String Variable
In Figure 2.1, assuming EBX contains three, "s[ebx]" does not access the fourth character in the string s, instead it fetches the fourth byte of the pointer to the string data. It is very unlikely that this is the desired effect you would want. Figure 2.2 shows the operation that is necessary to fetch a character from the string, assuming EBX contains the value of s:
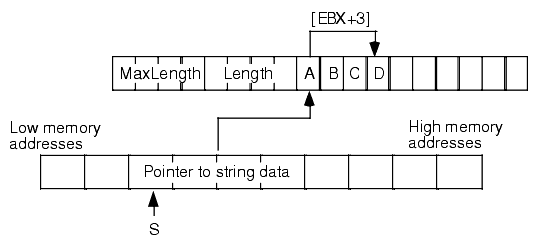
Figure 2.2 Correctly Indexing Off the Value of a String Variable
In Figure 2.2 EBX contains the value of string s. The value of s is a pointer to the actual string data in memory. Therefore, EBX will point at the first character of the string when you load the value of s into EBX. The following code demonstrates how to access the fourth character of string s in this fashion:
mov( s, ebx ); // Get pointer to string data into EBX. mov( [ebx+3], al ); // Fetch the fourth character of the string.If you want to load the character at a variable, rather than fixed, offset into the string, then you can use one of the 80x86's scaled indexed addressing modes to fetch the character. For example, if an uns32 variable index contains the desired offset into the string, you could use the following code to access the character at s[index]:
mov( s, ebx ); // Get address of string data into EBX. mov( index, ecx ); // Get desired offset into string. mov( [ebx+ecx], al ); // Get the desired character into AL.There is only one problem with the code above- it does not check to ensure that the character at offset index actually exists. If index is greater than the current length of the string, then this code will fetch a garbage byte from memory. Unless you can apriori determine that index is always less than the length of the string, code like this is dangerous to use. A better solution is to check the index against the string's current length before attempting to access the character. the following code provides one way to do this.
mov( s, ebx ); mov( index, ecx ); if( ecx < (type str.strRec [ebx]).Length ) then mov( [ebx+ecx], al ); else << error, string index is of bounds >> endif;In the ELSE portion of this IF statement you could take corrective action, print an error message, or raise an exception. If you want to explicitly raise an exception, you can use the HLA RAISE statement to accomplish this. The syntax for the RAISE statement is
raise( integer_constant ); raise( reg32 );The value of the integer_constant or 32-bit register must be an exception number. Usually, this is one of the predefined constants in the excepts.hhf header file. An appropriate exception to raise when a string index is greater than the length of the string is ex.StringIndexError. The following code demonstrates raising this exception if the string index is out of bounds:
mov( s, ebx ); mov( index, ecx ); if( ecx < (type str.strRec [ebx]).Length ) then mov( [ebx+ecx], al ); else raise( ex.StringIndexError ); endif;1Actually, there are some restrictions on the placement of HLA strings in memory. This text will not cover those issues. See the HLA documentation for more details.
2Note that this scheme is not recommended. If you need to extract the length information from a string, use the routines provided in the HLA string library for this purpose.
3Stralloc may allocate more than nine bytes for the overhead data because the memory allocated to an HLA string must always be double word aligned and the total length of the data structure must be an even multiple of four.
4Actually, there are limits on the maximum number of characters that stdin.a_gets will allocate. This is typically between 1,024 bytes and 4,096 bytes; See the HLA Standard Library source listings for the exact value.
|