match routine. The match routine returns failure or success depending on the state of the comparison. This isn't quite as easy as it sounds, though; learning how to construct the pattern data structure is almost like learning a new programming language. Fortunately, if you've followed the discussion on context free languages, learning this new "language" is a breeze.Pattern struct MatchFunction dword ? MatchParm dword ? MatchAlt dword ? NextPattern dword ? EndPattern word ? StartPattern word ? StrSeg word ? Pattern ends
The MatchFunction field contains the address of a routine to call to perform some sort of comparison. The success or failure of this function determines whether the pattern matches the input string. For example, the UCR Standard Library provides a MatchStr function that compares the next n characters of the input string against some other character string.
The MatchParm field contains the address or value of a parameter (if appropriate) for the MatchFunction routine. For example, if the MatchFunction routine is MatchStr, then the MatchParm field contains the address of the string to compare the input characters against. Likewise, the MatchChar routine compares the next input character in the string against the L.O. byte of the MatchParm field. Some matching functions do not require any parameters, they will ignore any value you assign to MatchParm field. By convention, most programmers store a zero in unused fields of the Pattern structure.
The MatchAlt field contains either zero (NULL) or the address of some other pattern data structure. If the current pattern matches the input characters, the pattern matching routines ignore this field. However, if the current pattern fails to match the input string, then the pattern matching routines will attempt to match the pattern whose address appears in this field. If this alternate pattern returns success, then the pattern matching routine returns success to the caller, otherwise it returns failure. If the MatchAlt field contains NULL, then the pattern matching routine immediately fails if the main pattern does not match.
The Pattern data structure only matches one item. For example, it might match a single character, a single string, or a character from a set of characters. A real world pattern will probably contain several small patterns concatenated together, e.g., the pattern for a Pascal identifier consists of a single character from the set of alphabetic characters followed by one or more characters from the set [a-zA-Z0-9_]. The NextPattern field lets you create a composite pattern as the concatenation of two individual patterns. For such a composite pattern to return success, the current pattern must match and then the pattern specified by the NextPattern field must also match. Note that you can chain as many patterns together as you please using this field.
The last three fields, EndPattern, StartPattern, and StrSeg are for the internal use of the pattern matching routine. You should not modify or examine these fields.
Once you create a pattern, it is very easy to test a string to see if it matches that pattern. The calling sequence for the UCR Standard Library match routine is
lesi << Input string to match »
ldxi << Pattern to match string against »
mov cx, 0
match
jc Success
The Standard Library match routine expects a pointer to the input string in the es:di registers; it expects a pointer to the pattern you want to match in the dx:si register pair. The cx register should contain the length of the string you want to test. If cx contains zero, the match routine will test the entire input string. If cx contains a nonzero value, the match routine will only test the first cx characters in the string. Note that the end of the string (the zero terminating byte) must not appear in the string before the position specified in cx. For most applications, loading cx with zero before calling match is the most appropriate operation.
On return from the match routine, the carry flag denotes success or failure. If the carry flag is set, the pattern matches the string; if the carry flag is clear, the pattern does not match the string. Unlike the examples given in earlier sections, the match routine does not modify the di register, even if the match succeeds. Instead, it returns the failure/success position in the ax register. The is the position of the first character after the match if match succeeds, it is the position of the first unmatched character if match fails.
spancset routine skips over all characters belonging to a character set. This routine will match zero or more characters in the specified set and, therefore, always succeeds. The MatchParm field of the pattern data structure must point at a UCR Standard Library character set variable.
SkipAlphas pattern {spancset, alpha}
.
.
.
lesi StringWAlphas
ldxi SkipAlphas
xor cx, cx
match
Brkcset is the dual to spancset - it matches zero or more characters in the input string which are not members of a specified character set. Another way of viewing brkcset is that it will match all characters in the input string up to a character in the specified character set (or to the end of the string). The matchparm field contains the address of the character set to match.
DoDigits pattern {brkcset, digits, 0, DoDigits2}
DoDigits2 pattern {spancset, digits}
.
.
.
lesi StringWDigits
ldxi DoDigits
xor cx, cx
match
jnc NoDigits
The code above matches any string that contains a string of one or more digits somewhere in the string.
Anycset matches a single character in the input string from a set of characters. The matchparm field contains the address of a character set variable. If the next character in the input string is a member of this set, anycset set accepts the string and skips over than character. If the next input character is not a member of that set, anycset returns failure.
DoID pattern {anycset, alpha, 0, DoID2}
DoID2 pattern {spancset, alphanum}
.
.
.
lesi StringWID
ldxi DoID
xor cx, cx
match
jnc NoID
This code segment checks the string StringWID to see if it begins with an identifier specified by the regular expression [a-zA-Z][a-zA-Z0-9]*. The first subpattern with anycset makes sure there is an alphabetic character at the beginning of the string (alpha is the stdsets.a set variable that has all the alphabetic characters as members). If the string does not begin with an alphabetic, the DoID pattern fails. The second subpattern, DoID2, skips over any following alphanumeric characters using the spancset matching function. Note that spancset always succeeds.
The above code does not simply match a string that is an identifier; it matches strings that begin with a valid identifier. For example, it would match "ThisIsAnID" as well as "ThisIsAnID+SoIsThis - 5". If you only want to match a single identifier and nothing else, you must explicitly check for the end of string in your pattern.
Notanycset provides the complement to anycset - it matches a single character in the input string that is not a member of a character set. The matchparm field, as usual, contains the address of the character set whose members must not appear as the next character in the input string. If notanycset successfully matches a character (that is, the next input character is not in the designated character set), the function skips the character and returns success; otherwise it returns failure.
DoSpecial pattern {notanycset, digits, 0, DoSpecial2}
DoSpecial2 pattern {spancset, alphanum}
.
.
.
lesi StringWSpecial
ldxi DoSpecial
xor cx, cx
match
jnc NoSpecial
This code is similar to the DoID pattern in the previous example. It matches a string containing any character except a digit and then matches a string of alphanumeric characters.
Matchstr compares the next set of input characters against a character string. The matchparm field contains the address of a zero terminated string to compare against. If matchstr succeeds, it returns the carry set and skips over the characters it matched; if it fails, it tries the alternate matching function or returns failure if there is no alternate.
DoString pattern {matchstr, MyStr}
MyStr byte "Match this!",0
.
.
.
lesi String
ldxi DoString
xor cx, cx
match
jnc NotMatchThis
This sample code matches any string that begins with the characters "Match This!"
Matchistr is like matchstr insofar as it compares the next several characters against a zero terminated string value. However, matchistr does a case insensitive comparison. During the comparison it converts the characters in the input string to upper case before comparing them to the characters that the matchparm field points at. Therefore, the string pointed at by the matchparm field must contain uppercase wherever alphabetics appear. If the matchparm string contains any lower case characters, the matchistr function will always fail.
DoString pattern {matchistr, MyStr}
MyStr byte "MATCH THIS!",0
.
.
.
lesi String
ldxi DoString
xor cx, cx
match
jnc NotMatchThis
This example is identical to the one in the previous section except it will match the characters "match this!" using any combination of upper and lower case characters.
Matchtostr matches all characters in an input string up to and including the characters specified by the matchparm parameter. This routine succeeds if the specified string appears somewhere in the input string, it fails if the string does not appear in the input string. This pattern function is quite useful for locating a substring and ignoring everything that came before the substring.
DoString pattern {matchtostr, MyStr}
MyStr byte "Match this!",0
.
.
.
lesi String
ldxi DoString
xor cx, cx
match
jnc NotMatchThis
Like the previous two examples, this code segment matches the string "Match this!" However, it does not require that the input string (String) begin with "Match this!" Instead, it only requires that "Match this!" appear somewhere in the string.
matchchar function matches a single character. The matchparm field's L.O. byte contains the character you want to match. If the next character in the input string is that character, then this function succeeds, otherwise it fails.
DoSpace pattern {matchchar, ' '}
.
.
.
lesi String
ldxi DoSpace
xor cx, cx
match
jnc NoSpace
This code segment matches any string that begins with a space. Keep in mind that the match routine only checks the prefix of a string. If you wanted to see if the string contained only a space (rather than a string that begins with a space), you would need to explicitly check for an end of string after the space. Of course, it would be far more efficient to use strcmp rather than match for this purpose!
Note that unlike matchstr, you encode the character you want to match directly into the matchparm field. This lets you specify the character you want to test directly in the pattern definition.
matchtostr, matchtochar matches all characters up to and including a character you specify. This is similar to brkcset except you don't have to create a character set containing a single member and brkcset skips up to but not including the specified character(s). Matchtochar fails if it cannot find the specified character in the input string.
DoToSpace pattern {matchtochar, ' '}
.
.
.
lesi String
ldxi DoSpace
xor cx, cx
match
jnc NoSpace
This call to match will fail if there are no spaces left in the input string. If there are, the call to matchtochar will skip over all characters up to, and including, the first space. This is a useful pattern for skipping over words in a string.
Matchchars skips zero or more occurrences of a singe character in an input string. It is similar to spancset except you can specify a single character rather than an entire character set with a single member. Like matchchar, matchchars expects a single character in the L.O. byte of the matchparm field. Since this routine matches zero or more occurrences of that character, it always succeeds.
Skip2NextWord pattern {matchtochar, ' ', 0, SkipSpcs}
SkipSpcs pattern {matchchars, ' '}
.
.
.
lesi String
ldxi Skip2NextWord
xor cx, cx
match
jnc NoWord
The code segment skips to the beginning of the next word in a string. It fails if there are no additional words in the string (i.e., the string contains no spaces).
Matchtopat matches all characters in a string up to and including the substring matched by some other pattern. This is one of the two facilities the UCR Standard Library pattern matching routines provide to allow the implementation of nonterminal function calls. This matching function succeeds if it finds a string matching the specified pattern somewhere on the line. If it succeeds, it skips the characters through the last character matched by the pattern parameter. As you would expect, the matchparm field contains the address of the pattern to match.
; Assume there is a pattern "expression" that matches arithmetic
; expressions. The following pattern determines if there is such an
; expression on the line followed by a semicolon.
FindExp pattern {matchtopat, expression, 0, MatchSemi}
MatchSemi pattern {matchchar, ';'}
.
.
.
lesi String
ldxi FindExp
xor cx, cx
match
jnc NoExp
EOS pattern matches the end of a string. This pattern, which must obviously appear at the end of a pattern list if it appears at all, checks for the zero terminating byte. Since the Standard Library routines only match prefixes, you should stick this pattern at the end of a list if you want to ensure that a pattern exactly matches a string with no left over characters at the end. EOS succeeds if it matches the zero terminating byte, it fails otherwise.
SkipNumber pattern {anycset, digits, 0, SkipDigits}
SkipDigits pattern {spancset, digits, 0, EOSPat}
EOSPat pattern {EOS}
.
.
.
lesi String
ldxi SkipNumber
xor cx, cx
match
jnc NoNumber
The SkipNumber pattern matches strings that contain only decimal digits (from the start of the match to the end of the string). Note that EOS requires no parameters, not even a matchparm parameter.
ARB matches any number of arbitrary characters. This pattern matching function is equivalent to  *. Note that
*. Note that ARB is a very inefficient routine to use. It works by assuming it can match all remaining characters in the string and then tries to match the pattern specified by the nextpattern field. If the nextpattern item fails, ARB backs up one character and tries matching nextpattern again. This continues until the pattern specified by nextpattern succeeds or ARB backs up to its initial starting position. ARB succeeds if the pattern specified by nextpattern succeeds, it fails if it backs up to its initial starting position.ARB (especially on long strings), you should try to avoid using this pattern if at all possible. The matchtostr, matchtochar, and matchtopat functions accomplish much of what ARB accomplishes, but they work forward rather than backward in the source string and may be more efficient. ARB is useful mainly if you're sure the following pattern appears late in the string you're matching or if the string you want to match occurs several times and you want to match the last occurrence (matchtostr, matchtochar, and matchtopat always match the first occurrence they find).
SkipNumber pattern {ARB,0,0,SkipDigit}
SkipDigit pattern {anycset, digits, 0, SkipDigits}
SkipDigits pattern {spancset, digits}
.
.
.
lesi String
ldxi SkipNumber
xor cx, cx
match
jnc NoNumber
This code example matches the last number that appears on an input line. Note that ARB does not use the matchparm field, so you should set it to zero by default.
ARBNUM matches an arbitrary number (zero or more) of patterns that occur in the input string. If R represents some nonterminal number (pattern matching function), then ARBNUM(R ) is equivalent to the production ARBNUM 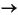 R ARBNUM |
R ARBNUM | 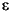 .
.matchparm field contains the address of the pattern that ARBNUM attempts to match.
SkipNumbers pattern {ARBNUM, SkipNumber}
SkipNumber pattern {anycset, digits, 0, SkipDigits}
SkipDigits pattern {spancset, digits, 0, EndDigits}
EndDigits pattern {matchchars, ' ', EndString}
EndString pattern {EOS}
.
.
.
lesi String
ldxi SkipNumbers
xor cx, cx
match
jnc IllegalNumbers
This code accepts the input string if it consists of a sequence of zero or more numbers separated by spaces and terminated with the EOS pattern. Note the use of the matchalt field in the EndDigits pattern to select EOS rather than a space for the last number in the string.
Skip matches n arbitrary characters in the input string. The matchparm field is an integer value containing the number of characters to skip. Although the matchparm field is a double word, this routine limits the number of characters you can skip to 16 bits (65,535 characters); that is, n is the L.O. word of the matchparm field. This should prove sufficient for most needs.Skip succeeds if there are at least n characters left in the input string; it fails if there are fewer than n characters left in the input string.
Skip1st6 pattern {skip, 6, 0, SkipNumber}
SkipNumber pattern {anycset, digits, 0, SkipDigits}
SkipDigits pattern {spancset, digits, 0, EndDigits}
EndDigits pattern {EOS}
.
.
.
lesi String
ldxi Skip1st6
xor cx, cx
match
jnc IllegalItem
This example matches a string containing six arbitrary characters followed by one or more decimal digits and a zero terminating byte.
Pos succeeds if the matching functions are currently at the nth character in the string, where n is the value in the L.O. word of the matchparm field. Pos fails if the matching functions are not currently at position n in the string. Unlike the pattern matching functions you've seen so far, pos does not consume any input characters. Note that the string starts out at position zero. So when you use the pos function, it succeeds if you've matched n characters at that point.
SkipNumber pattern {anycset, digits, 0, SkipDigits}
SkipDigits pattern {spancset, digits, 0, EndDigits}
EndDigits pattern {pos, 4}
.
.
.
lesi String
ldxi SkipNumber
xor cx, cx
match
jnc IllegalItem
This code matches a string that begins with exactly 4 decimal digits.
Rpos works quite a bit like the pos function except it succeeds if the current position is n character positions from the end of the string. Like pos, n is the L.O. 16 bits of the matchparm field. Also like pos, rpos does not consume any input characters.
SkipNumber pattern {anycset, digits, 0, SkipDigits}
SkipDigits pattern {spancset, digits, 0, EndDigits}
EndDigits pattern {rpos, 4}
.
.
.
lesi String
ldxi SkipNumber
xor cx, cx
match
jnc IllegalItem
This code matches any string that is all decimal digits except for the last four characters of the string. The string must be at least five characters long for the above pattern match to succeed.
Gotopos skips over any characters in the string until it reaches character position n in the string. This function fails if the pattern is already beyond position n in the string. The L.O. word of the matchparm field contains the value for n.
SkipNumber pattern {gotopos, 10, 0, MatchNmbr}
MatchNmbr pattern {anycset, digits, 0, SkipDigits}
SkipDigits pattern {spancset, digits, 0, EndDigits}
EndDigits pattern {rpos, 4}
.
.
.
lesi String
ldxi SkipNumber
xor cx, cx
match
jnc IllegalItem
This example code skips to position 10 in the string and attempts to match a string of digits starting with the 11th character. This pattern succeeds if the there are four characters remaining in the string after processing all the digits.
Rgotopos works like gotopos except it goes to the position specified from the end of the string. Rgotopos fails if the matching routines are already beyond position n from the end of the string. As with gotopos, the L.O. word of the matchparm field contains the value for n.
SkipNumber pattern {rgotopos, 10, 0, MatchNmbr}
MatchNmbr pattern {anycset, digits, 0, SkipDigits}
SkipDigits pattern {spancset, digits}
.
.
.
lesi String
ldxi SkipNumber
xor cx, cx
match
jnc IllegalItem
This example skips to ten characters from the end of the string and then attempts to match one or digits starting at that point. It fails if there aren't at least 11 characters in the string or the last 10 characters don't begin with a string of one or more digits.
sl_match2 routine is nothing more than a recursive call to match. The matchparm field contains the address of pattern to match. This is quite useful for simulating parenthesis around a pattern in a pattern expression. As far as matching strings are concerned, pattern1 and pattern2, below, are equivalent:
Pattern2 pattern {sl_match2, Pattern1}
Pattern1 pattern {matchchar, 'a'}
The only difference between invoking a pattern directly and invoking it with sl_match2 is that sl_match2 tweaks some internal variables to keep track of matching positions within the input string. Later, you can extract the character string matched by sl_match2 using the patgrab routine.