
Chapter Ten Classes and Objects
10.1 Chapter Overview
Many modern imperative high level languages support the notion of classes and objects. C++ (an object version of C), Java, and Delphi (an object version of Pascal) are two good examples. Of course, these high level language compilers translate their high level source code into low-level machine code, so it should be pretty obvious that some mechanism exists in machine code for implementing classes and objects.
Although it has always been possible to implement classes and objects in machine code, most assemblers provide poor support for writing object-oriented assembly language programs. Of course, HLA does not suffer from this drawback as it provides good support for writing object-oriented assembly language programs. This chapter discusses the general principles behind object-oriented programming (OOP) and how HLA supports OOP.
10.2 General Principles
Before discussing the mechanisms behind OOP, it is probably a good idea to take a step back and explore the benefits of using OOP (especially in assembly language programs). Most texts describing the benefits of OOP will mention buzz-words like "code reuse," "abstract data types," "improved development efficiency," and so on. While all of these features are nice and are good attributes for a programming paradigm, a good software engineer would question the use of assembly language in an environment where "improved development efficiency" is an important goal. After all, you can probably obtain far better efficiency by using a high level language (even in a non-OOP fashion) than you can by using objects in assembly language. If the purported features of OOP don't seem to apply to assembly language programming, why bother using OOP in assembly? This section will explore some of those reasons.
The first thing you should realize is that the use of assembly language does not negate the aforementioned OOP benefits. OOP in assembly language does promote code reuse, it provides a good method for implementing abstract data types, and it can improve development efficiency in assembly language. In other words, if you're dead set on using assembly language, there are benefits to using OOP.
To understand one of the principle benefits of OOP, consider the concept of a global variable. Most programming texts strongly recommend against the use of global variables in a program (as does this text). Interprocedural communication through global variables is dangerous because it is difficult to keep track of all the possible places in a large program that modify a given global object. Worse, it is very easy when making enhancements to accidentally reuse a global object for something other than its intended purpose; this tends to introduce defects into the system.
Despite the well-understood problems with global variables, the semantics of global objects (extended lifetimes and accessibility from different procedures) are absolutely necessary in various situations. Objects solve this problem by letting the programmer decide on the lifetime of an object1 as well as allow access to data fields from different procedures. Objects have several advantages over simple global variables insofar as objects can control access to their data fields (making it difficult for procedures to accidentally access the data) and you can also create multiple instances of an object allowing two separate sections of your program to use their own unique "global" object without interference from the other section.
Of course, objects have many other valuable attributes. One could write several volumes on the benefits of objects and OOP; this single chapter cannot do this subject justice. The following subsections present objects with an eye towards using them in HLA/assembly programs. However, if you are a beginning to OOP or wish more information about the object-oriented paradigm, you should consult other texts on this subject.
An important use for classes and objects is to create abstract data types (ADTs). An abstract data type is a collection of data objects and the functions (which we'll call methods) that operate on the data. In a pure abstract data type, the ADT's methods are the only code that has access to the data fields of the ADT; external code may only access the data using function calls to get or set data field values (these are the ADT's accessor methods). In real life, for efficiency reasons, most languages that support ADTs allow, at least, limited access to the data fields of an ADT by external code.
Assembly language is not a language most people associate with ADTs. Nevertheless, HLA provides several features to allow the creation of rudimentary ADTs. While some might argue that HLA's facilities are not as complete as those in a language such as C++ or Java, keep in mind that these differences exist because HLA is assembly language.
True ADTs should support information hiding. This means that the ADT does not allow the user of an ADT access to internal data structures and routines which manipulate those structures. In essence, information hiding restricts access to an ADT to only the accessor methods provided by the ADT. Assembly language, of course, provides very few restrictions. If you are dead set on accessing an object directly, there is very little HLA can do to prevent you from doing this. However, HLA has some facilities which will provide a small amount of information hiding capabilities. Combined with some care on your part, you will be able to enjoy many of the benefits of information hiding within your programs.
The primary facility HLA provides to support information hiding is separate compilation, linkable modules, and the #INCLUDE/#INCLUDEONCE directives. For our purposes, an abstract data type definition will consist of two sections: an interface section and an implementation section.
The interface section contains the definitions which must be visible to the application program. In general, it should not contain any specific information which would allow the application program to violate the information hiding principle, but this is often impossible given the nature of assembly language. Nevertheless, you should attempt to only reveal what is absolutely necessary within the interface section.
The implementation section contains the code, data structures, etc., to actually implement the ADT. While some of the methods and data types appearing in the implementation section may be public (by virtue of appearance within the interface section), many of the subroutines, data items, and so on will be private to the implementation code. The implementation section is where you hide all the details from the application program.
If you wish to modify the abstract data type at some point in the future, you will only have to change the interface and implementation sections. Unless you delete some previously visible object which the applications use, there will be no need to modify the applications at all.
Although you could place the interface and implementation sections directly in an application program, this would not promote information hiding or maintainability, especially if you have to include the code in several different applications. The best approach is to place the implementation section in an include file that any interested application reads using the HLA #INCLUDE directive and to place the implementation section in a separate module that you link with your applications.
The include file would contain EXTERNAL directives, any necessary macros, and other definitions you want made public. It generally would not contain 80x86 code except, perhaps, in some macros. When an application wants to make use of an ADT it would include this file.
The separate assembly file containing the implementation section would contain all the procedures, functions, data objects, etc., to actually implement the ADT. Those names which you want to be public should appear in the interface include file and have the EXTERNAL attribute. You should also include the interface include file in the implementation file so you do not have to maintain two sets of EXTERNAL directives.
One problem with using procedures for data access methods is the fact that many accessor methods are especially trivial (typically just a MOV instruction) and the overhead of the call and return instructions is expensive for such trivial operations. For example, suppose you have an ADT whose data object is a structure, but you do not want to make the field names visible to the application and you really do not want to allow the application to access the fields of the data structure directly (because the data structure may change in the future). The normal way to handle this is to supply a method GetField which returns the desired field of the object. However, as pointed out above, this can be very slow. An alternative, for simple access methods is to use a macro to emit the code to access the desired field. Although code to directly access the data object appears in the application program (via macro expansion), it will be automatically updated if you ever change the macro in the interface section by simply assembling your application.
Although it is quite possible to create ADTs using nothing more than separate compilation and, perhaps, RECORDs, HLA does provide a better solution: the class. Read on to find out about HLA's support for classes and objects as well as how to use these to create ADTs.
10.3 Classes in HLA
HLA's classes provide a good mechanism for creating abstract data types. Fundamentally, a class is little more than a RECORD declaration that allows the definition of fields other than data fields (e.g., procedures, constants, and macros). The inclusion of other program declaration objects in the class definition dramatically expands the capabilities of a class over that of a record. For example, with a class it is now possible to easily define an ADT since classes may include data and methods that operate on that data (procedures).
The principle way to create an abstract data type in HLA is to declare a class data type. Classes in HLA always appear in the TYPE section and use the following syntax:
classname : class << Class declaration section >> endclass;The class declaration section is very similar to the local declaration section for a procedure insofar as it allows CONST, VAL, VAR, and STATIC variable declaration sections. Classes also let you define macros and specify procedure, iterator, and method prototypes (method declarations are legal only in classes). Conspicuously absent from this list is the TYPE declaration section. You cannot declare new types within a class.
A method is a special type of procedure that appears only within a class. A little later you will see the difference between procedures and methods, for now you can treat them as being one and the same. Other than a few subtle details regarding class initialization and the use of pointers to classes, their semantics are identical2. Generally, if you don't know whether to use a procedure or method in a class, the safest bet is to use a method.
You do not place procedure/iterator/method code within a class. Instead you simply supply prototypes for these routines. A routine prototype consists of the PROCEDURE, ITERATOR, or METHOD reserved word, the routine name, any parameters, and a couple of optional procedure attributes (@USE, RETURNS, and EXTERNAL). The actual routine definition (i.e., the body of the routine and any local declarations it needs) appears outside the class.
The following example demonstrates a typical class declaration appearing in the TYPE section:
TYPE TypicalClass: class const TCconst := 5; val TCval := 6; var TCvar : uns32; // Private field used only by TCproc. static TCstatic : int32; procedure TCproc( u:uns32 ); returns( "eax" ); iterator TCiter( i:int32 ); external; method TCmethod( c:char ); endclass;As you can see, classes are very similar to records in HLA. Indeed, you can think of a record as being a class that only allows VAR declarations. HLA implements classes in a fashion quite similar to records insofar as it allocates sequential data fields in sequential memory locations. In fact, with only one minor exception, there is almost no difference between a RECORD declaration and a CLASS declaration that only has a VAR declaration section. Later you'll see exactly how HLA implements classes, but for now you can assume that HLA implements them the same as it does records and you won't be too far off the mark.
You can access the TCvar and TCstatic fields (in the class above) just like a record's fields. You access the CONST and VAL fields in a similar manner. If a variable of type TypicalClass has the name obj, you can access the fields of obj as follows:
mov ( obj.TCconst, eax ); mov( obj.TCval, ebx ); add( obj.TCvar, eax ); add( obj.TCstatic, ebx ); obj.TCproc( 20 ); // Calls the TCproc procedure in TypicalClass. etc.If an application program includes the class declaration above, it can create variables using the TypicalClass type and perform operations using the above methods. Unfortunately, the application program can also access the fields of the ADT data type with impunity. For example, if a program created a variable MyClass of type TypicalClass, then it could easily execute instructions like "MOV( MyClass.TCvar, eax );" even though this field might be private to the implementation section. Unfortunately, if you are going to allow an application to declare a variable of type TypicalClass, the field names will have to be visible. While there are some tricks we could play with HLA's class definitions to help hide the private fields, the best solution is to thoroughly comment the private fields and then exercise some restraint when accessing the fields of that class. Specifically, this means that ADTs you create using HLA's classes cannot be "pure" ADTs since HLA allows direct access to the data fields. However, with a little discipline, you can simulate a pure ADT by simply electing not to access such fields outside the class' methods, procedures, and iterators.
Prototypes appearing in a class are effectively FORWARD declarations. Like normal forward declarations, all procedures, iterators, and methods you define in a class must have an actual implementation later in the code. Alternately, you may attach the EXTERNAL keyword to the end of a procedure, iterator, or method declaration within a class to inform HLA that the actual code appears in a separate module. As a general rule, class declarations appear in header files and represent the interface section of an ADT. The procedure, iterator, and method bodies appear in the implementation section which is usually a separate source file that you compile separately and link with the modules that use the class.
The following is an example of a sample class procedure implementation:
procedure TypicalClass.TCproc( u:uns32 ); nodisplay; << Local declarations for this procedure >> begin TCproc; << Code to implement whatever this procedure does >> end TCProc;There are several differences between a standard procedure declaration and a class procedure declaration. First, and most obvious, the procedure name includes the class name (e.g., TypicalClass.TCproc). This differentiates this class procedure definition from a regular procedure that just happens to have the name TCproc. Note, however, that you do not have to repeat the class name before the procedure name in the BEGIN and END clauses of the procedure (this is similar to procedures you define in HLA NAMESPACEs).
A second difference between class procedures and non-class procedures is not obvious. Some procedure attributes (@USE, EXTERNAL, RETURNS, @CDECL, @PASCAL, and @STDCALL) are legal only in the prototype declaration appearing within the class while other attributes (@NOFRAME, @NODISPLAY, @NOALIGNSTACK, and ALIGN) are legal only within the procedure definition and not within the class. Fortunately, HLA provides helpful error messages if you stick the option in the wrong place, so you don't have to memorize this rule.
If a class routine's prototype does not have the EXTERNAL option, the compilation unit (that is, the PROGRAM or UNIT) containing the class declaration must also contain the routine's definition or HLA will generate an error at the end of the compilation. For small, local, classes (i.e., when you're embedding the class declaration and routine definitions in the same compilation unit) the convention is to place the class' procedure, iterator, and method definitions in the source file shortly after the class declaration. For larger systems (i.e., when separately compiling a class' routines), the convention is to place the class declaration in a header file by itself and place all the procedure, iterator, and method definitions in a separate HLA unit and compile them by themselves.
10.4 Objects
Remember, a class definition is just a type. Therefore, when you declare a class type you haven't created a variable whose fields you can manipulate. An object is an instance of a class; that is, an object is a variable that is some class type. You declare objects (i.e., class variables) the same way you declare other variables: in a VAR, STATIC, or STORAGE section3. A pair of sample object declarations follow:
var T1: TypicalClass; T2: TypicalClass;For a given class object, HLA allocates storage for each variable appearing in the VAR section of the class declaration. If you have two objects, T1 and T2, of type TypicalClass then T1.TCvar is unique as is T2.TCvar. This is the intuitive result (similar to RECORD declarations); most data fields you define in a class will appear in the VAR declaration section.
Static data objects (e.g., those you declare in the STATIC section of a class declaration) are not unique among the objects of that class; that is, HLA allocates only a single static variable that all variables of that class share. For example, consider the following (partial) class declaration and object declarations:
type sc: class var i:int32; static s:int32; . . . endclass; var s1: sc; s2: sc;In this example, s1.i and s2.i are different variables. However, s1.s and s2.s are aliases of one another Therefore, an instruction like "mov( 5, s1.s);" also stores five into s2.s. Generally you use static class variables to maintain information about the whole class while you use class VAR objects to maintain information about the specific object. Since keeping track of class information is relatively rare, you will probably declare most class data fields in a VAR section.
You can also create dynamic instances of a class and refer to those dynamic objects via pointers. In fact, this is probably the most common form of object storage and access. The following code shows how to create pointers to objects and how you can dynamically allocate storage for an object:
var pSC: pointer to sc; . . . malloc( @size( sc ) ); mov( eax, pSC ); . . . mov( pSC, ebx ); mov( (type sc [ebx]).i, eax );Note the use of type coercion to cast the pointer in EBX as type sc.
10.5 Inheritance
Inheritance is one of the most fundamental ideas behind object-oriented programming. The basic idea behind inheritance is that a class inherits, or copies, all the fields from some class and then possibly expands the number of fields in the new data type. For example, suppose you created a data type point which describes a point in the planar (two dimensional) space. The class for this point might look like the following:
type point: class var x:int32; y:int32; method distance; endclass;Suppose you want to create a point in 3D space rather than 2D space. You can easily build such a data type as follows:
type point3D: class inherits( point ); var z:int32; endclass;The INHERITS option on the CLASS declaration tells HLA to insert the fields of point at the beginning of the class. In this case, point3D inherits the fields of point. HLA always places the inherited fields at the beginning of a class object. The reason for this will become clear a little later. If you have an instance of point3D which you call P3, then the following 80x86 instructions are all legal:
mov( P3.x, eax ); add( P3.y, eax ); mov( eax, P3.z ); P3.distance();Note that the P3.distance method invocation in this example calls the point.distance method. You do not have to write a separate distance method for the point3D class unless you really want to do so (see the next section for details). Just like the x and y fields, point3D objects inherit point's methods.
10.6 Overriding
Overriding is the process of replacing an existing method in an inherited class with one more suitable for the new class. In the point and point3D examples appearing in the previous section, the distance method (presumably) computes the distance from the origin to the specified point. For a point on a two-dimensional plane, you can compute the distance using the function:
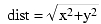
However, the distance for a point in 3D space is given by the equation:
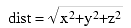
Clearly, if you call the distance function for point for a point3D object you will get an incorrect answer. In the previous section, however, you saw that the P3 object calls the distance function inherited from the point class. Therefore, this would produce an incorrect result.
In this situation the point3D data type must override the distance method with one that computes the correct value. You cannot simply redefine the point3D class by adding a distance method prototype:
type point3D: class inherits( point ) var z:int32; method distance; // This doesn't work! endclass;The problem with the distance method declaration above is that point3D already has a distance method - the one that it inherits from the point class. HLA will complain because it doesn't like two methods with the same name in a single class.
To solve this problem, we need some mechanism by which we can override the declaration of point.distance and replace it with a declaration for point3D.distance. To do this, you use the OVERRIDE keyword before the method declaration:
type point3D: class inherits( point ) var z:int32; override method distance; // This will work! endclass;The OVERRIDE prefix tells HLA to ignore the fact that point3D inherits a method named distance from the point class. Now, any call to the distance method via a point3D object will call the point3D.distance method rather than point.distance. Of course, once you override a method using the OVERRIDE prefix, you must supply the method in the implementation section of your code, e.g.,
method point3D.distance; nodisplay; << local declarations for the distance function>> begin distance; << Code to implement the distance function >> end distance;10.7 Virtual Methods vs. Static Procedures
A little earlier, this chapter suggested that you could treat class methods and class procedures the same. There are, in fact, some major differences between the two (after all, why have methods if they're the same as procedures?). As it turns out, the differences between methods and procedures is crucial if you want to develop object-oriented programs. Methods provide the second feature necessary to support true polymorphism: virtual procedure calls4. A virtual procedure call is just a fancy name for an indirect procedure call (using a pointer associated with the object). The key benefit of virtual procedures is that the system automatically calls the right method when using pointers to generic objects.
Consider the following declarations using the point class from the previous sections:
var P2: point; P: pointer to point;Given the declarations above, the following assembly statements are all legal:
mov( P2.x, eax ); mov( P2.y, ecx ); P2.distance(); // Calls point3D.distance. lea( ebx, P2 ); // Store address of P2 into P. mov( ebx, P ); P.distance(); // Calls point.distance.Note that HLA lets you call a method via a pointer to an object rather than directly via an object variable. This is a crucial feature of objects in HLA and a key to implementing virtual method calls.
The magic behind polymorphism and inheritance is that object pointers are generic. In general, when your program references data indirectly through a pointer, the value of the pointer should be the address of the underlying data type associated with that pointer. For example, if you have a pointer to a 16-bit unsigned integer, you wouldn't normally use that pointer to access a 32-bit signed integer value. Similarly, if you have a pointer to some record, you would not normally cast that pointer to some other record type and access the fields of that other type5. With pointers to class objects, however, we can lift this restriction a bit. Pointers to objects may legally contain the address of the object's type or the address of any object that inherits the fields of that type. Consider the following declarations that use the point and point3D types from the previous examples:
var P2: point; P3: point3D; p: pointer to point; . . . lea( ebx, P2 ); mov( ebx, p ); p.distance(); // Calls the point.distance method. . . . lea( ebx, P3 ); mov( ebx, p ); // Yes, this is semantically legal. p.distance(); // Surprise, this calls point3D.distance.Since p is a pointer to a point object, it might seem intuitive for p.distance to call the point.distance method. However, methods are polymorphic. If you've got a pointer to an object and you call a method associated with that object, the system will call the actual (overridden) method associated with the object, not the method specifically associated with the pointer's class type.
Class procedures behave differently than methods with respect to overridden procedures. When you call a class procedure indirectly through an object pointer, the system will always call the procedure associated with the underlying class associated with the pointer. So had distance been a procedure rather than a method in the previous examples, the "p.distance();" invocation would always call point.distance, even if p is pointing at a point3D object. The section on Object Initialization, later in this chapter, explains why methods and procedures are different (see "Object Implementation" on page 1071).
Note that iterators are also virtual; so like methods an object iterator invocation will always call the (overridden) iterator associated with the actual object whose address the pointer contains. To differentiate the semantics of methods and iterators from procedures, we will refer to the method/iterator calling semantics as virtual procedures and the calling semantics of a class procedure as a static procedure.
1That is, the time during which the system allocates memory for an object.
2Note, however, that the difference between procedures and methods makes all the difference in the world to the object-oriented programming paradigm. Hence the inclusion of methods in HLA's class definitions.
3Technically, you could also declare an object in a READONLY section, but HLA does not allow you to define class constants, so there is little utility in declaring class objects in the READONLY section.
4Polymorphism literally means "many-faced." In the context of object-oriented programming polymorphism means that the same method name, e.g., distance, and refer to one of several different methods.
5Of course, assembly language programmers break rules like this all the time. For now, let's assume we're playing by the rules and only access the data using the data type associated with the pointer.
|